
Securing the Forms Authentication Cookie with Secure Flag
Filed under: Development, Security
One of the recommendations for securing cookies within a web application is to apply the Secure attribute. Typically, this is only a browser directive to direct the browser to only include the cookie with a request if it is over HTTPS. This helps prevent the cookie from being sent over an insecure connection, like HTTP. There is a special circumstance around the Microsoft .Net Forms Authentication cookie that I want to cover as it can become a difficult challenge.
The recommended way to set the secure flag on the forms authentication cookie is to set the requireSSL attribute in the web.config as shown below:
<authentication mode="Forms">
<forms name="Test.web" defaultUrl="~/Default" loginUrl="~/Login" path="/" requireSSL="true" protection="All" timeout="20" slidingExpiration="true"/>
</authentication>In the above code, you can see that requireSSL is set to true.
In your login code, you would have code similar to this once the user is properly validated:
FormsAuthentication.SetAuthCookie(userName, false);In this case, the application will automatically set the secure attribute.

Simple, right? In most cases this is very straight forward. Sometimes, it isn’t.
Removing HTTPS on Internal Networks
There are many occasions where the application may remove HTTPS on the internal network. This is commonly seen, or used to be commonly seen, when the application is behind a load balancer. The end user would connect using HTTPS over the internet to the load balancer and then the load balancer would connect to the application server over HTTP. One common reason for this was easier inspection of internal network traffic for monitoring by the organization.
Why Does This Matter? Isn’t the Secure Attribute of a Cookie Browser Only?
There was an interesting decision made by Microsoft when they created .Net Forms Authentication. A decision was made to verify that the connection to the application server is secure if the requireSSL attribute is set on the authentication cookie (specified above in the web.config example), when the cookie is set using FormsAuthentication.SetCookie(). This is the only cookie that the code checks to verify it is on a secure connection.
This means that if you set requireSSL in the web.config for the forms authentication cookie and the request to the server is over HTTP, .Net will throw an exception.
This code can be seen in https://github.com/microsoft/referencesource/blob/master/System.Web/Security/FormsAuthenticationModule.cs in the ExtractTicketFromCookie method:

The obvious solution is to enable HTTPS on the traffic all the way to the application server. But sometimes as developers, we don’t have that control.
What Can We Do?
There are two options I want to discus. This first one actually doesn’t provide a complete solution, even though it seems like it would.
FormsAuthentication.GetAuthCookie
At first glance, FormsAuthentication.GetAuthCookie might seem like a good option. Instead of using SetAuthCookie, which we know will break the application in this case, one might try to call GetAuthCookie and just manage the cookie themselves. Here is what that might look like, once the user is validated.
var cookie = FormsAuthentication.GetAuthCookie(userName, false);
cookie.Secure = true;
HttpContext.Current.Response.Cookies.Add(cookie);Rather than call SetAuthCookie, here we are trying to just get a new AuthCookie and we can set the secure flag and then add it to the cookies collection manually. This is similar to what the SetAuthCookie method does, with the exception that it is not setting the secure flag based on the web.config setting. That is the key difference here.
Keep in mind that GetAuthCookie returns a new auth ticket each time it is called. It does not return the ticket or cookie that was created if you previously called SetAuthCookie.
So why doesn’t this work completely?
Upon initial testing, this method appears to work. If you run the application and log in, you will see that the cookie does have the secure flag set. This is just like our initial response at the beginning of this article. The issue here comes with SlidingExpiration. If you remember, in our web.config, we had SlidingExpiration set to true (the default is true, so it was set in the config just for visual aide).
<authentication mode="Forms">
<forms name="Test.web" defaultUrl="~/Default" loginUrl="~/Login" path="/" requireSSL="true" protection="All" timeout="20" slidingExpiration="true"/>
</authentication>Sliding expiration means that once the ticket is reached over 1/2 of its age and is submitted with a request, it will auto renew. This allows a user that is active to not have to re-authentication after the timeout. This re-authentication occurs again in https://github.com/microsoft/referencesource/blob/master/System.Web/Security/FormsAuthenticationModule.cs in the OnAuthenticate method.

We can see in the above code that the secure flag is again being set by the FormsAuthentication.RequireSSL web.config setting. So even though we jumped through some hoops to set it manually during the initial authentication, every ticket renewal will reset it back to the config setting.
In our web.config we had a timeout set to 20 minutes. So requesting a page after 12 minutes will result in the application setting a new FormsAuth cookie without the Secure attribute.
This option would most likely get scanners and initial testers to believe the problem was remediated. However, after a potentially short period of time (depending on your timeout setting), the cookie becomes insecure again. I don’t recommend trying to set the secure flag in this manner.
Option 2 – Global.asax
Another option is to use the Global.asax Application_EndRequest event to set the cookie to secure. With this configuration, the web.config would not set requireSSL to true and the authentication would just use the FormsAuthentication.SetAuthCookie() method. Then, in the Global.asax file we could have something similar to the following code.
protected void Application_EndRequest(object sender, EventArgs e)
{
if(Response.Cookies.Count > 0)
{
for(int i = 0; i < Response.Cookies.Count; i++)
{
//Response.Cookies[i].Secure = true;
}
}
}The above code will loop through all the cookies setting the secure flag on them on every request. It is possible to go one step further and check the cookie name to see if it matches the forms authentication cookie before setting the secure flag, but hopefully your site runs on HTTPS so there should be no harm in all cookies having the secure flag set.
There have been debate on how well this method works based on when the EndRequest event will fire and if it fires for all requests or not. In my local testing, this method appears to work and the secure flag is set properly. However, that was local testing with minimal traffic. I cannot verify the effectiveness on a site with heavy loads or load balancing or other configurations. I recommend testing this out thoroughly before using it.
Conclusion
For something that should be so simple, this situation can be a headache for developers that don’t have any control over the connection to their application. In the end, the ideal situation would be to enable HTTPS to the application server so the requireSSL flag can be set in the web.config. If that is not possible, then there are some workarounds that will hopefully work. Make sure you are doing the appropriate testing to verify the workaround works 100% of the time and not just once or twice. Otherwise, you may just be checking a box to show an example of it being marked secure, when it is not in all cases.
Disabling SpellCheck on Sensitive Fields
Filed under: Development, Security
Do you know what happens when a browser performs spell checking on an input field?
Depending on the configuration of the browser, for example with the enhanced spell check feature of Chrome, it may be sending those values out to Google. This could potentially put sensitive data at risk so it may be a good idea to disable spell checking on those fields. Let’s see how we can do this.
Simple TextBox
<input type=“text” spellcheck=“false”>
Text Area
<textarea spellcheck=“false”></textarea>
You could also cover the entire form by setting it at the form level as shown below:
<form spellcheck=“false”>
Conclusion
It is important to point out that password fields can also be vulnerable to this if they have the “show password” option. In these cases, it is recommended to disable spell checking on the password field as well as other sensitive fields.
If the field might be sensitve, and doesn’t benefit from spellcheck, it might be a good idea to disable this feature.
What is the difference between encryption and hashing?
Filed under: Development, Security
Encryption is a reversible process, whereas hashing is one-way only. Data that has been encrypted can be decrypted back to the original value. Data that has been hashed cannot be transformed back to its original value.
Encryption is used to protect sensitive information like Social Security Numbers, credit card numbers or other sensitive information that may need to be accessed at some point.
Hashing is used to create data signatures or comparison only features. For example, user passwords used for login should be hashed because the program doesn’t need to store the actual password. When the user attempts to log in, the system will generate a hash of the supplied password using the same technique as the one stored and compare them. If they match, the passwords are the same.
Another example scenario with hashing is with file downloads to verify integrity. The supplier of the file will create a hash of the file on the server so when you download the file you can then generate the hash locally and compare them to make sure the file is correct.
XmlSecureResolver: XXE in .Net
Filed under: Development, Security, Testing
tl;dr
- Microsoft .Net 4.5.2 and above protect against XXE by default.
- It is possible to become vulnerable by explicitly setting a XmlUrlResolver on an XmlDocument.
- A secure alternative is to use the XmlSecureResolver object which can limit allowed domains.
- XmlSecureResolver appeared to work correctly in .Net 4.X, but did not appear to work in .Net 6.
I wrote about XXE in .net a few years ago (https://www.jardinesoftware.net/2016/05/26/xxe-and-net/) and I recently starting doing some more research into how it works with the later versions. At the time, the focus was just on versions prior to 4.5.2 and then those after it. At that time there wasn’t a lot after it. Now we have a few versions that have appeared and I started looking at some examples.
I stumbled across the XmlSecureResolver class. It peaked my curiosity, so I started to figure out how it worked. I started with the following code snippet. Note that this was targeting .Net 6.0.
static void Load()
{
string xml = "<?xml version='1.0' encoding='UTF-8' ?><!DOCTYPE foo [<!ENTITY xxe SYSTEM 'https://labs.developsec.com/test/xxe_test.php'>]><root><doc>&xxe;</doc><foo>Test</foo></root>";
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.XmlResolver = new XmlSecureResolver(new XmlUrlResolver(), "https://www.jardinesoftware.com");
xmlDoc.LoadXml(xml);
Console.WriteLine(xmlDoc.InnerText);
Console.ReadLine();
}So what is the expectation?
- At the top of the code, we are setting some very simple XML
- The XML contains an Entity that is attempting to pull data from the labs.developsec.com domain.
- The xxe_test.php file simply returns “test from the web..”
- Next, we create an XmlDocument to parse the xml variable.
- By Default (after .net 4.5.1), the XMLDocument does not parse DTDs (or external entities).
- To Allow this, we are going to set the XmlResolver. In This case, we are using the XmlSecureResolver assuming it will help limit the entities that are allowed to be parsed.
- I will set the XmlSecureResolver to a new XmlUrlResolver.
- I will also set the permission set to limit entities to the jardinesoftware.com domain.
- Finally, we load the xml and print out the result.
My assumption was that I should get an error because the URL passed into the XmlSecureResolver constructor does not match the URL that is referenced in the xml string’s entity definition.
https://www.jardinesoftware.com != https://labs.developsec.com
Can you guess what result I received?
If you guessed that it worked just fine and the entity was parsed, you guessed correct. But why? The whole point of XMLSecureResolver is to be able to limit this to only entities from the allowed domain.
I went back and forth for a few hours trying different configurations. Accessing different files from different locations. It worked every time. What was going on?
I then decided to switch from my Mac over to my Windows system. I loaded up Visual Studio 2022 and pulled up my old project from the old blog post. The difference? This project was targeting the .Net 4.8 framework. I ran the exact same code in the above snippet and sure enough, I received an error. I did not have permission to access that domain.
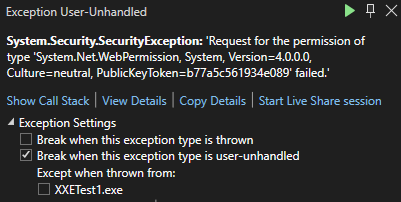
Finally, success. But I wasn’t satisfied. Why was it not working on my Mac. So I added the .Net 6 SDK to my Windows system and changed the target. Sure enough, no exception was thrown and everything worked fine. The entity was parsed.
Why is this important?
The risk around parsing XML like this is a vulnerability called XML External Entities (XXE). The short story here is that it allows a malicious user to supply an XML document that references external files and, if parsed, could allow the attacker to read the content of those files. There is more to this vulnerability, but that is the simple overview.
Since .net 4.5.2, the XmlDocument object was protected from this vulnerability by default because it sets the XmlResolver to null. This blocks the parser from parsing any external entities. The concern here is that a user may have decided they needed to allow entities from a specific domain and decided to use the XmlSecureResolver to do it. While that seemed to work in the 4.X versions of .Net, it seems to not work in .Net 6. This can be an issue if you thought you were good and then upgraded and didn’t realize that the functionality changed.
Conclusion
If you are using the XmlSecureResolver within your .Net application, make sure that it is working as you expect. Like many things with Microsoft .Net, everything can change depending on the version you are running. In my test cases, .Net 4.X seemed to work properly with this object. However, .Net 6 didn’t seem to respect the object at all, allowing DTD parsing when it was unexpected.
I did not opt to load every version of .Net to see when this changed. It is just another example where we have to be conscious of the security choices we make. It could very well be this is a bug in the platform or that they are moving away from using this an a way to allow specific domains. In either event, I recommend checking to see if you are using this and verifying if it is working as expected.
Input Validation for Security
Filed under: Development, Security
Validating input is an important step for reducing risk to our applications. It might not eliminate the risk, and for that reason we should consider what exactly we are doing with input validation.
Should you be looking for every attack possible?
Should you create a list of every known malicious payload?
When you think about input validation are you focusing on things like Cross-site Scripting, SQL Injection, or XXE, just to name a few? How feasible is it to attempt to block all these different vulnerabilities with input validation? Are each of these even a concern for your application?
I think that input validation is important. I think it can help reduce the ability for many of these vulnerabilities. I also think that our expectation should be aligned with what we can be doing with input validation. We shouldn’t overlook these vulnerabilities, but instead realize appropriate limitations. All of these vulnerabilities have a counterpart, such as escaping, output encoding, parser configurations, etc. that will complete the appropriate mitigation.
If we can’t, or shouldn’t, block all vulnerabilities with input validation, what should we focus on?
Start with focusing on what is acceptable data. It might be counter-intuitive, but malicious data could be acceptable data from a data requirements statement. We define our acceptable data with specific constraints. These typically fall under the following categories:
* Range – What are the bounds of the data? ex. Age can only be between 0 and 150.
* Type – What type of data is it? Integer, Datetime, String.
* Length – How many characters should be allow?
* Format – Is there a specific format? Ie. SSN or Account Number
As noted, these are not specifically targeting any vulnerability. They are narrowing the capabilities. If you verify that a value is an Integer, it is hard to get typical injection exploits. This is similar to custom format requirements. Limiting the length also restricts malicious payloads. A state abbreviation field with a length of 2 is much more difficult to exploit.
The most difficult type is the string. Here you may have more complexity and depending on your purpose, might actually have more specific attacks you might look for. Maybe you allow some HTML or markup in the field. In that case, you may have more advanced input validation to remove malicious HTML or events.
There is nothing wrong with using libraries that will help look for malicious attack payloads during your input validation. However, the point here is to not spend so much time focusing on blocking EVERYTHING when that is not necessary to get the product moving forward. Understand the limitation of that input validation and ensure that the complimenting controls like output encoding are properly engaged where they need to be.
The final point I want to make on input validation is where it should happen. There are two options: on the client, or on the server. Client validation is used for immediate feedback to the user, but it should never be used for security.
It is too easy to bypass client-side validation routines, so all validation should also be checked on the server. The user doesn’t have the ability to bypass controls once the data is on the server. Be careful with how you try to validate things on the client directly.
Like anything we do with security, understand the context and reasoning behind the control. Don’t get so caught up in trying to block every single attack that you never release. There is a good chance something will get through your input validation. That is why it is important to have other controls in place at the point of impact. Input validation limits the amount of bad traffic that can get to the important functions, but the functions still may need to do additional processes to be truly secure.
Chrome is making some changes… Are you Ready?
Filed under: Development, Security
Last year, Chrome announced that it was making a change to default cookies to SameSite:Lax if there is no SameSite setting explicitly set. I wrote about this change last year (https://www.jardinesoftware.net/2019/10/28/samesite-by-default-in-2020/). This change could have an impact on some sites, so it is important that you test this out. The changes are supposed to start rolling out in February (this month). The linked post shows how to force these defaults in both FireFox and Chrome.
In addition to this, Chrome has announced that it is going to start blocking mixed-content downloads (https://blog.chromium.org/2020/02/protecting-users-from-insecure.html). In this case, they are starting in Chrome 83 (June 2020) with blocking executable file downloads (.exe, .apk) that are over HTTP but requested from an HTTPS site.
The issue at hand is that users are mislead into thinking the download is secure due to the requesting page indicating it is over HTTPS. There isn’t a way for them to clearly see that the request is insecure. The linked Chrome blog describes a timeline of how they will slowly block all mixed-content types.
For many sites this might not be a huge concern, but this is a good time to check your sites to determine if you have any type of mixed content and ways to mitigate this.
You can identify mixed content on your site by using the Javascript Console. It can be found under the Developer Tools in your browser. This will prompt a warning when it identifies mixed content. There may also be some scanners you can use that will crawl your site looking for mixed content.
To help mitigate this from a high level, you could implement CSP to upgrade insecure requests:
Content-Security-Policy: upgrade-insecure-requests
This can help by upgrading insecure requests, but it is not supported in all browsers. The following post goes into a lot of detail on mixed content and some ways to resolve it: https://developers.google.com/web/fundamentals/security/prevent-mixed-content/fixing-mixed-content
The increase in protections of the browsers can help reduce the overall threats, but always remember that it is the developer’s responsibility to implement the proper design and protections. Not all browsers are the same and you can’t rely on the browser to provide all the protections.
XXE DoS and .Net
External XML Entity (XXE) vulnerabilities can be more than just a risk of remote code execution (RCE), information leakage, or server side request forgery (SSRF). A denial of service (DoS) attack is commonly overlooked. However, given a mis-configured XML parser, it may be possible for an attacker to cause a denial of service attack and block your application’s resources. This would limit the ability for a user to access the expected application when needed.
In most cases, the parser can be configured to just ignore any entities, by disabling DTD parsing. As a matter of fact, many of the common parsers do this by default. If the DTD is not processed, then even the denial of service risk should be removed.
For this post, I want to talk about if DTDs are parsed and focus specifically on the denial of service aspect. One of the properties that becomes important when working with .Net and XML is the MaxCharactersFromEntities property.
The purpose of this property is to limit how long the value of an entity can be. This is important because often times in a DoS attempt, the use of expanding entities can cause a very large request with very few actual lines of data. The following is an example of what a DoS attack might look like in an entity.
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE foo [ <!ELEMENT foo ANY > <!ENTITY dos 'dos' > <!ENTITY dos1 '&dos;&dos;&dos;&dos;&dos;&dos;&dos;&dos;&dos;&dos;&dos;&dos;' > <!ENTITY dos2 '&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;&dos1;' > <!ENTITY dos3 '&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;&dos2;' > <!ENTITY dos4 '&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;&dos3;' > <!ENTITY dos5 '&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;&dos4;' > <!ENTITY dos6 '&dos5;&dos5;&dos5;&dos5;&dos5;&dos5;&dos5;&dos5;&dos5;&dos5;&dos5;&dos5;' >]>
Notice in the above example we have multiple entities that each reference the previous one multiple times. This results in a very large string being created when dos6 is actually referenced in the XML code. This would probably not be large enough to actually cause a denial of service, but you can see how quickly this becomes a very large value.
To help protect the XML parser and the application the MaxCharactersFromEntities helps limit how large this expansion can get. Once it reaches the max amount, it will throw a System.XmlXmlException: ‘The input document has exceeded a limit set by MaxCharactersFromEntities’ exception.
The Microsoft documentation (linked above) states that the default value is 0. This means that it is undefined and there is no limit in place. Through my testing, it appears that this is true for ASP.Net Framework versions up to 4.5.1. In 4.5.2 and above, as well as .Net Core, the default value for this property is 10,000,000. This is most likely a small enough value to protect against denial of service with the XmlReader object.
Overview of Web Security Policies
Filed under: Development, Security, Testing
A vulnerability was just identified in your website. How would you know?
The process of vulnerability disclosure to an organization is often very difficult to identify. Whether you are offering any type of bounty for security bugs or not, it is important that there is a clear path for someone to notify you of a potential concern.
Unfortunately, the process is different on every application and it can be very difficult to find it. For someone that is just trying to help out, it can be very frustrating as well. Some websites may have a separate security page with contact information. Other sites may just have a security email address on the contact us page. Many sites don’t have any clear indication of how to report such a finding. Maybe we could just use the security@ email address for the organization, but do they have it configured?
In an effort to help standardize how to find this information, there is a draft definition for a method for web security policies. You can read the draft at https://tools.ietf.org/html/draft-foudil-securitytxt-03. The goal of this is to specify a text file in a known path to provide contact information for users to submit potential security concerns.
How it works
The first step is to create a security.txt file to describe your web security policy. This file should be found in the .well-known directory (according to the specifications). This would make your text file found at /.well-known/security.txt. In some circumstances, it may also be found at just /security.txt.
The purpose of pinning down the name of the file and where it should be located is to limit the searching process. If someone finds an issue, they know where to go to find the right contact information or process.
The next step is to put the relevant information into the security.txt file. The draft documentation covers this in depth, but I want to give a quick example of what this may look like:
Security.txt
— Start of File —
# This is a sample security.txt file contact: mailto:james@developsec.com contact: tel:+1-904-638-5431 # Encryption - This links to my public PGP Key Encryption: https://www.jardinesoftware.com/jamesjardine-public.txt # Policy - Links to a policy page outlining what you are looking for Policy: https://www.jardinesoftware.com/security-policy # Acknowledgments - If you have a page that acknowledges users that have submitted a valid bug Acknowledgments: https://www.jardinesoftware.com/acknowledgments # Hiring - if you offer security related jobs, put the link to that page here Hiring: https://www.jardinesoftwarre.com/jobs # Signature - To help secure your file, create a signature file and reference it here. Signature: https://www.jardinesoftware.com/.well-known/security.txt.sig
—- End of File —
I included some comments in that sample above to show what each item is for. A key point is that very little policy information is actually included in the file, rather it is linked as a reference. For example, the PGP key is not actually embedded in the file, but instead the link to the key is referenced.
The goal of the file is to be in a well defined location and provide references to your different security policies and procedures.
WHAT DO YOU THINK?
So I am curious, what do you think about this technique? While it is still in draft status, it is an interesting concept. It allows providing a known path for organizations to follow to provide this type of information.
I don’t believe it is a requirement to create bug bounty programs, or even promote the security testing of your site without permission. However, it does at least provide a means to share your requests and provide information to someone that does find a flaw and wants to share that information with you.
Will we see this move forward, or do you think it will not catch on? If it is a good idea, what is the best way to raise the awareness of it?
XSS in Script Tag
Filed under: Development, Security, Testing
Cross-site scripting is a pretty common vulnerability, even with many of the new advances in UI frameworks. One of the first things we mention when discussing the vulnerability is to understand the context. Is it HTML, Attribute, JavaScript, etc.? This understanding helps us better understand the types of characters that can be used to expose the vulnerability.
In this post, I want to take a quick look at placing data within a <script> tag. In particular, I want to look at how embedded <script> tags are processed. Let’s use a simple web page as our example.
<html> <head> </head> <body> <script> var x = "<a href=test.html>test</a>"; </script> </body> </html>
The above example works as we expect. When you load the page, nothing is displayed. The link tag embedded in the variable is rated as a string, not parsed as a link tag. What happens, though, when we embed a <script> tag?
<html> <head> </head> <body> <script> var x = "<script>alert(9)</script>"; </script> </body> </html>
In the above snippet, actually nothing happens on the screen. Meaning that the alert box does not actually trigger. This often misleads people into thinking the code is not vulnerable to cross-site scripting. if the link tag is not processed, why would the script tag be. In many situations, the understanding is that we need to break out of the (“) delimiter to start writing our own JavaScript commands. For example, if I submitted a payload of (test”;alert(9);t = “). This type of payload would break out of the x variable and add new JavaScript commands. Of course, this doesn’t work if the (“) character is properly encoded to not allow breaking out.
Going back to our previous example, we may have overlooked something very simple. It wasn’t that the script wasn’t executing because it wasn’t being parsed. Instead, it wasn’t executing because our JavaScript was bad. Our issue was that we were attempting to open a <script> within a <script>. What if we modify our value to the following:
<html> <head> </head> <body> <script> var x = "</script><script>alert(9)</script>"; </script> </body> </html>
In the above code, we are first closing out the original <script> tag and then we are starting a new one. This removes the embedded nuance and when the page is loaded, the alert box will appear.
This technique works in many places where a user can control the text returned within the <script> element. Of course, the important remediation step is to make sure that data is properly encoded when returned to the browser. By default, Content Security Policy may not be an immediate solution since this situation would indicate that inline scripts are allowed. However, if you are limiting the use of inline scripts to ones with a registered nonce would help prevent this technique. This reference shows setting the nonce (https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy/script-src).
When testing our applications, it is important to focus on the lack of output encoding and less on the ability to fully exploit a situation. Our secure coding standards should identify the types of encoding that should be applied to outputs. If the encodings are not properly implemented then we are citing a violation of our standards.
Security Tips for Copy/Paste of Code From the Internet
Filed under: Development, Security
Developing applications has long involved using code snippets found through textbooks or on the Internet. Rather than re-invent the wheel, it makes sense to identify existing code that helps solve a problem. It may also help speed up the development time.
Years ago, maybe 12, I remember a co-worker that had a SQL Injection vulnerability in his application. The culprit, code copied from someone else. At the time, I explained that once you copy code into your application it is now your responsibility.
Here, 12 years later, I still see this type of occurrence. Using code snippets directly from the web in the application. In many of these cases there may be some form of security weakness. How often do we, as developers, really analyze and understand all the details of the code that we copy?
Here are a few tips when working with external code brought into your application.
Understand what it does
If you were looking for code snippets, you should have a good idea of what the code will do. Better yet, you probably have an understanding of what you think that code will do. How vigorously do you inspect it to make sure that is all it does. Maybe the code performs the specific task you were set out to complete, but what happens if there are other functions you weren’t even looking for. This may not be as much a concern with very small snippets. However, with larger sections of code, it could coverup other functionality. This doesn’t mean that the functionality is intentionally malicious. But undocumented, unintended functionality may open up risk to the application.
Change any passwords or secrets
Depending on the code that you are searching, there may be secrets within it. For example, encryption routines are common for being grabbed off the Internet. To be complete, they contain hard-coded IVs and keys. These should be changed when imported into your projects to something unique. This could also be the case for code that has passwords or other hard-coded values that may provide access to the system.
As I was writing this, I noticed a post about the RadAsyncUpload control regarding the defaults within it. While this is not code copy/pasted from the Internet, it highlights the need to understand the default configurations and that some values should be changed to help provide better protections.
Look for potential vulnerabilities
In addition to the above concerns, the code may have vulnerabilities in it. Imagine a snippet of code used to select data from a SQL database. What if that code passed your tests of accurately pulling the queries, but uses inline SQL and is vulnerable to SQL Injection. The same could happen for code vulnerable to Cross-Site Scripting or not checking proper authorization.
We have to do a better job of performing code reviews on these external snippets, just as we should be doing it on our custom written internal code. Finding snippets of code that perform our needed functionality can be a huge benefit, but we can’t just assume it is production ready. If you are using this type of code, take the time to understand it and review it for potential issues. Don’t stop at just verifying the functionality. Take steps to vet the code just as you would any other code within your application.
Follow Us


