
Your Passwords Were Stolen: What’s Your Plan?
Filed under: Development, Security
If you have been glancing at many news stories this year, you have certainly seen the large number of data breaches that have occurred. Even just today, we are seeing reports that Drupal.org suffered from a breach (https://drupal.org/news/130529SecurityUpdate) that shows unauthorized access to hashed passwords, usernames, and email addresses. Note that this is not a vulnerability in the CMS product, but the actual website for Drupal.org. Unfortunately, Drupal is just the latest to report this issue.
In addition to Drupal, LivingSocial also suffered a huge breach involving passwords. LinkedIn, Evernote, Yahoo, and Name.com have also joined this elite club. In each of these cases, we have seen many different formats for storing the passwords. Some are using plain text (ouch), others are actually doing what has been recommended and using a salted hash. Even with a salted hash, there are still some issues. One, hashes are fast and some hashes are not as strong as others. Bad choices can lead to an immediate failure in implementation and protection.
Going into what format you should store your passwords in will be saved for another post, and has been discusses heavily on the internet. It is really outside the scope of this post, because in this discussion, it is already too late for that. Here, I want to ask the simple question of, “You have been breached, What do you do?”
Ok, Maybe it is not a simple question, or maybe it is. Most of the sites that have seen these breaches are fairly quick to force password resets by all of their users. The idea behind this is that the credentials were stolen, but only the actual user should be able to perform a password reset. The user performs the reset, they have new credentials, and the information that the bad guy got (and everyone else that downloads the stolen credentials) are no good. Or maybe not?? Wait.. you re-use passwords across multiple sites? Well, that makes it more interesting. I guess you now need to reset a bunch of passwords.
Reseting passwords appears to be the standard. I haven’t seen anyone else attempt to do anything else, if you have please share. But what else would work? You can’t just change the algorithm to make it stronger.. the bad guy has the password. Changing the algorithm doesn’t change that fact and they just log in using a stronger algorithm. I guess that won’t work. Might be nice to have a mechanism to upgrade everyone to a stronger algorithm as time goes on though.
So if resetting passwords in mass appears to work and is the standard, do you have a way to do it? if you got breached today, what would you need to do to reset everyone’s password, or at least force a password reset on all users? There are a few options, and of course it depends on how you actually manage user passwords.
If you have a password expiration field in the DB, you could just set all passwords to have expired yesterday. Now everyone will be presented with an expired password prompt. The problem with this solution is if an expired password just requires the old password to set the new password. It is possible the bad guy does this before the actual user. Oops.
You could Just null out or put in a 0 or some false value into all of the password fields. This only works for encrypted or hashed passwords.. not clear text. This could be done with a simple SQL Update statement, just drop that needless where clause ;). When a user goes to log in, they will be unsuccessful because when the password they submit is encrypted or hashed, it will never match the value you updated the field to. This forces them to use the forgot password field.
You could run a separate application that resets everyone password like the previous method, it just doesn’t run a DB Update directly on the server. Maybe you are a control freak as to what gets run against the servers and control that access.
As you can see, there are many ways to do this, but have you really given it any thought? Have you written out your plan that in the event your site gets breached like these other sites, you will be able to react intelligently and swiftly? Often times when we think of incidence response, we think of stopping the attack, but we also have to think about how we would protect our users from future attacks quickly.
These ideas are just a few examples of how you can go about this to help provoke you and your team to think about how you would do this in your situation. Every application is different and this scenario should be in your IR plan. If you have other ways to handle this, please share with everyone.
ViewState: Still Mis-understood
Filed under: Development, Security
Here we are in 2013 and we are still having discussions about what ViewState is and how it works. For you MVC guys and gals, you are probably even wondering who is still using it. Although I do find it interesting that we have ViewState in Webforms but not in MVC even though MVC has the Views. Does that make anyone else wonder?
A few weeks ago, I was in the midst of a Twitter discussion where there was some different ideas about ViewState floating around. It really started when the idea came across to use Encryption for your ViewState to prevent tampering. While I do agree 100% that encrypting your ViewState will prevent someone from tampering it, I feel that it adds quite a bit of overhead when it shouldn’t be needed. A general rule of thumb that I use with ViewState is that you shouldn’t be storing anything sensitive in it. There are other mechanisms for storing sensitive information, and the client is your last, last, last choice (or shouldn’t be a choice at all).
My response, why not just use ViewStateMac? The whole point of ViewStateMac is to protect the ViewState from tampering. It is on by default, and doesn’t require encrypting all of your ViewState and then decrypting it.
For those of you who don’t know, ViewState is a .Net specific client-side storage mechanism. By default, it is used to store the state of your view. I know, webforms don’t have views per se.. But that is what it does. It stores the values for your label controls, the items in your drop down lists, data in your datagrid, etc. This data is then used on a postback to re-populate the server-side controls. For example, if there is a label on the form (say copyright), when the form is submitted and re-displayed the text for that label is populated automatically from the ViewState. This saves the developer from having to reset the value on every response.
Another example is with a drop down list. All of the values are stored in the ViewState. When the user submits the form, the drop down list is re-populated from the ViewState. This does a few things. First, it keeps the developer from having to populate the list from the original data source for every response and request. Of course, there are other ways to save the hit to the original data source and store it in session or some other quick storage. Second, it is basically a version of a reference map. When done correctly, it is not possible for an attacker to submit a value that didn’t exist in the drop down list. This really helps when it comes to parameter tampering on these fields. Of course there are ways to program this where it doesn’t protect you but that is beyond this post.
So far, everything we have looked at in ViewState is visible anyway. Why encrypt it?
I have seen some really bad things stored in ViewState. I have seen RACF usernames and passwords, full connection strings, and lots of other stuff. To be blunt, those should never be in there.
So again, if we are not storing this sensitive information in ViewState, why encrypt it? If the answer is just tamper protection, my opinion is to just go with the ViewStateMac.
When I do an assessment on a web application, one of my favorite things to do is look at the ViewState. Of course, I love to see when MAC is not enabled. Most of the time, ViewStateMac is enabled and I don’t get much from the ViewState. I get confirmation, that the developers aren’t storing sensitive information in there and they are properly protecting it. When I see that the ViewState is encrypted, it sends off some bells in my head. Why are they encrypting this ViewState? Maybe they do have something to hide. Maybe there is a reason for me to dig into it and see if I can’t break the encryption to see what it is.
One additional point I would like to make is that ViewState is not meant to be storage across pages. It is meant to be storage for a single web form.
I was called out on the Twitter chat as loving ViewState. I wouldn’t go that far, but I don’t have much ill will toward it. It has a purpose and can be quite useful if used properly. Of course, it can be a great help to an attacker if not used properly.
I enjoyed the discussion on Twitter, unfortunately sometimes 140 characters is not really enough to get ideas across. I would be curious if anyone has any other thoughts on this topic on how ViewState should work and pros and cons for encrypting ViewState over just setting ViewStateMac. Feel free to reach out to me.
Hidden Treasures: Not So Hidden
Filed under: Development, Security, Testing
For years now, I have run into developers that believe that just because a request can’t be seen, it is not vulnerable to flaws. Wait, what are we talking about here? What do you mean by a request that can’t be seen? There are a few different ways that the user would not see a request. For example, Ajax requests are invisible to users. What about framed pages? Except for the main parent, all of the other pages are hidden from the user’s view. These are what I would call hidden requests.
Lets use a framed site as an example. Lets say that a page has multiple frames embedded in it, each leading to a different page of content. From a user perspective, I would normally only see the URL in the Address Bar of the parent page that contains the other frames. Although each frame has its own URL, I don’t see it natively. This type of out-of-site out-of-mind thought process often leads us to over look the security of these pages.
There are all sorts of vulnerabilities that can be present in the scenario above. I have seen SQL injection, Direct Object Reference and Authorization issues. BUT THEY ARE HIDDEN??
To the naked eye, yes, they are hidden. Unfortunately, there are numerous tools available to see these requests. Web Proxies are the most popular, although there are some browser add-ins that also may do the trick. The two proxies I used the most are Burp and Fiddler. Both of these tools are used to intercept and record all of the HTTP/HTTPS traffic between your browser and the server. This means that even though I might not see the URL or the request in the browser, I will see it in the proxy.
Many years ago, I came across this exact scenario. We had a website that used frames and one of the framed pages used parameters on the querystring. This parameter just happened to be vulnerable to SQL Injection. The developer didn’t think anything of this because you never saw the parameters. All it took was just breaking the page out of the frame and directly modifying the value in the address bar, or using a proxy to capture and manipulate the request to successfully exploit the flaw.
It was easy to fix the problem, as the developer updated his SQL to use parameterized queries instead of dynamic SQL, but this just shows how easy it is to overlook issues that can’t be seen.
In another instance, I saw a page that allowed downloading files based on a querystring value. During normal use of the application you might never see that request, just the file downloading. Using a proxy, it was easy to not only identify the request, but identify that it was a great candidate for finding a security flaw. When we reported the flaw, I was asked multiple times about how I found the flaw. It was another case where the developer thought that because the request wasn’t displayed anywhere, no one would find it.
There are many requests that go unseen in the address bar of the web browser. We must remember that as developers, it is our responsibility to properly secure all of our code, whether or not they appear in the address bar. I encourage all developers to use web proxies while testing and developing their applications so they can be aware of all the transactions that are actually made.
Brute Force: An Inside Job
Filed under: Development, Security, Testing
As a developer, we are told all the time to protect against brute force attacks on the login screen by using a mechanism like account lockouts. We even see this on our operating systems, when we attempt multiple incorrect logins, we get locked out. Of course, as times have changed, so have some of the mitigations. For example, some systems are implementing a Captcha or some other means to slow down automated brute force attacks. Of course, the logistics are different on every system, how many attempts until lockout, or is there an auto-unlock feature, but that is outside the scope of this post.
As a penetration tester, brute force attacks are something I test for on every application. Obviously, I test the login forms for this type of security flaw. There are also other areas of an application that brute force attacks can be effective. The one I want to discuss in this post is related to functionality inside the authenticated section of the application. More specifically, the change password screen. Done right, the change password screen will require the current password. This helps protect from a lot of different attacks. For example, if an attacker hijacks a user’s valid session, he wouldn’t be able to just change the user’s password. It also helps protect against cross-site request forgery for changing a user’s password. I know, I know, it can be argued with cross-site scripting available, cross-site request forgery can still be performed, but that gets a little more advanced.
What about brute forcing the change password screen? I rarely see during an assessment where the developers, or business has thought about this attack vector. In just about every case, I, the penetration tester, can attempt password changes with a bad password as much as I want, followed by a valid current password to change the password. What if an attacker hijacks my session? What if someone sits down at my desk while I have stepped away and I didn’t lock my computer (look around your office and see how many people lock their computer when they walk away)?
It is open season for an attacker to attempt a brute force attack to change the user’s password. You may wonder why we need to change the password if we have accessed the account. The short answer is persistence. I want to be able to access the account whenever I want. Maybe I don’t want the user to be able to get back in and fully take over the account.
So how do we address this? We don’t want to lock the account do we? My opinion is no, we don’t want to lock the account. Rather, lets just end the current session in this type of event. If the application can detect that the user is not able to type the correct current password three or five times in a given time frame (sounds familiar to account lockout procedures) then just end the current session. The valid user should know their password and not be mis-typing it a bunch of times. An invalid user should rightfully so get booted out of the system. If the valid user’s session ends, they just log back in, however the attacker shouldn’t be able to just log back in and may have to hijack the session again which may be difficult.
Just like other brute forcible features,there are other mitigations. A Captcha could also be used to slow down automation. The key differentiator here is that we are not locking the account, but possibly just ending the session. This will have less impact on technical support as the valid user can just log back in. Of course, don’t forget you should be logging these failed attempts and auditing them to detect this attack happening.
This type of security flaw is common, not because of lazy development, but because this is fairly unknown in the development world. Rarely are we thinking about this type of issue within the application, but we need to start. Just like implementing lockouts on the login screens, there is a need to protect that functionality on the inside.
Developers, Security, Business – Lets All Work Together
Filed under: Development, Security
A few years ago, my neighbors ran into an issue with each other. Unfortunately for one neighbor, the other neighbor was on the board for the HOA. The first neighbor decided to put up a fence, got the proper approvals and started work on it. They were building the fence them selves and it took a while to complete. The other neighbor, on the board of the HOA, noticed that the fence was being built out of compliance. Rather than stopping by and letting the first neighbor know about this, they decided it would be better to let them complete the fence and then issue a citation about the fence being out of compliance, requiring them to rebuild it. At times, I feel like I see the same thing in application security which leads into my post below.
There have been lots of great blogs lately talking about application security and questioning who’s responsibility the security of applications is (Matt Neely – Who is Responsible for Application Security?) and why we are still not producing secure applications (Rafal Los – Software Security – Why aren’t the enterprise developers listening?). I feel a little late to the party, even though I have been thinking about this post for over a week. At least I am not the only one thinking about this topic as the new year starts off.
There has been a great divide between security personnel and the development teams. This has been no secret. They don’t hang out at the same conferences and honestly, it looks similar to a high school dance where, in this case, the security people are on one side of the gym and the developers are on the other. Add in the chaperones (the business leadership) enforcing space between the two groups. We need to find a way to fix this and work together.
The first thing we have to do is realize that security is everyone’s responsibility. This is because building applications involves so many more people than just some developers. Is SQL Injection the outcome of insecure coding, most definitely yes it is. However, that is why development teams have layers. There are those writing code, but there are also testers involved with verifying that the developer didn’t miss something. People make mistakes, and that is why we put a second and third pair of eyes on things. If developers were perfect and did everything right the first time, would there even be a need for QA? QA is a big part to this puzzle, lets get them involved.
I don’t know if anyone else feels this, but I feel as though there is this condescending tone that comes from both sides. Developers don’t think they need security to come in and test and security has this notion that because they found a vulnerability that “I win” and “you lose.” We start security presentations off with “developers suck” or “we are going to pick on you today”, but why does it have to be that way. Constructive criticism is one thing, but lets be somewhat civil about it. Who wants to go the extra mile to fix applications when it comes across as a put down to the developers. This isn’t boot camp where we need to destroy all morale and then build them up the way we want.
I challenge the security guys to think about this when they are getting ready to criticize the developers. What if the situation were reversed, and you were required to find EVERY security issue in an application? Would you feel any pressure? How would you feel if you missed just one simple thing because you were under a time crunch to get the assessment done? I know, the standard response is that is why you chose the security field, so you didn’t have that requirement. I accept that response, but just want to encourage you to think about it when working with the teams that are fixing these issues. Fortunately, security practitioners don’t have this pressure, they just have to find something and throw a disclaimer that they don’t verify that the app doesn’t have other issues that were not identified during the test. Not everyone can choose to be in security, if they did, we wouldn’t have anyone developing. Don’t tell anyone… but if no one develops, there isn’t a whole lot left to manage security on. Interesting circle of life we have here.
This is not all about attitude coming from security. It goes both ways, and many times it can be worse from the dev side. I can’t tell you how many times I have seen it where the developers are upset as soon as they hear that their application is going through a penetration test. People mumbling about how their app is secure and how they don’t need the test. Unfortunately, there are many reasons why applications need to be tested by a third party. It is a part of development, get used to it. The good news is that these assessments are beneficial in multiple ways. First, you get another pair of eyes reviewing your app for stuff probably no one else on your team is thinking of. Second, you are given a chance to learn something new from the results of the test. Take the time to understand what the results are and incorporate the education into your programming. There are positives that come out of this.
Developers also need to start taking responsibility to understand and practice secure coding skills. This is paramount because so many vulnerabilities are due to just insecure coding. This involves much more than just the developers though. As I mentioned in a previous post, we need to do a better job of making this information available to the developers. Writing a book or tutorial, include secure coding examples, rather than short examples that are insecure. Making easier resources for developers to find when looking for secure coding principles. Many times, it is difficult to find a good example of how to do something because everyone is afraid if they give you something and it later becomes vulnerable they will be liable (blog post for another lifetime). Even intro to programming courses should demonstrate how to do secure programming. How difficult is it for an intro course to show using parameterized queries instead of dynamic queries? Same function, however one is secure. Why even show dynamic queries, that should be under the advanced section. Lets start pushing this from the start.
Eoin Keary recently posted XSS = SQLI = CMDi=? talking about the terminology used in security and how we look at the same type of vulnerability in so many different ways. I couldn’t agree more with what he wrote and I talk about this in the SANS Dev544: Secure Coding in .Net course. I can’t count how many times I point out that the resolution for so many of these different vulnerabilities is the same. Encode your output when sending to a different system. I understand that everyone wants to be the first to discover a new class of vulnerability, but we do need to start getting realistic when we work with the “builders” as Eoin refers to them as to what the vulnerabilities really are. If as a developer I don’t have 24 vulnerabilities I have to learn and understand, but realize that is really just 5 vulnerabilities, that makes it easier to start protecting against them. We need to get better at communicating what the problem is without over complicating it. I understand that the risk may be different for SQL Injection or Cross Site Scripting, but to a developer they are encoding untrusted data used for output in another system.
I think this year is off to a good start with all the conversations being held. There are some really smart people starting to think harder about how we can solve the problem. As you can hopefully see from the large amount of ranting above, this is not any one groups fault for this not working. There is contention from both sides. And don’t get me wrong, there are a lot of folks from both sides that are doing things right. Developers that are happy to see a pen test and security folks supporting the development side. We need to stay positive with each other and each think about how we interact with each other. We all have one goal and that is to improve the quality and security of our systems. Lets not lose focus of that.
ASP.Net and CSRF
Filed under: Development, Security
Cross-site request forgery (CSRF) is a very common vulnerability today. Like most frameworks, ASP.Net is not immune by default. There are some features that are built-in that can be enabled to help reduce the surface area of this attack, however we need to be aware of how they work and what situations they may not work in. First, lets provide a quick review of what CSRF is.
CRSF Overview
CSRF is really a result of the browser’s willingness to submit cookies to the server they are associated with. Of course, this has to happen so that your sessions stay active and you don’t have to enter your credentials on every request. The problem is when the request to one site (say site A) is made by a second site (say site B) without your permission or interaction. Lets take a look at a quick example of what we are talking about.
Say we have a site that allows deleting users by the administrator. The administrator is provided with a table listing all the users and a link to delete each one. That link looks something like this:
http://www.jardinesoftware.com/delete.aspx?userid=6
When an administrator clicks this link, the application first checks to see if he is authenticated (using the session or authentication cookie) and authorized. It then calls the functions responsible to delete the user with the id of 6.
The issue here, is that there is nothing unique in this request. If another users (without administrative rights) learns of this URL then it may be possible to get an administrator to run it for him. Here is how that works:
- The attacker crafts the request he wants to be executed by the administrator. In this case, it could be http://www.jardinesoftware.com/delete.aspx?userid=8.
- The attacker sends the administrative email an email containing this link (probably obfuscated so they don’t realize it is calling the delete function on the website. The attacker could also send a link to a seemingly innocent site, but contain an image tag containing a src attribute pointing to the delete link above.
- The victim (administrator) MUST already be logged into the application when he clicks the link.
- The browser sees the request for JardineSoftware.com and kindly appends the cookies for that domain.
- The server receives the cookies (for authentication) and the request and processes it. The server has no way of knowing that the user didn’t actually initiate the request on purpose.
- The user is deleted and the admin is none the wiser.
To resolve this, we need something to make the request unique. When the request is unique, it is difficult for the attacker to know that unique value for the victim so the request will fail. With the presence of XSS, many times this can be bypassed. There are many different ways to do this, which we will cover next. Keep in mind that each solution described below has its pros and cons that we must be aware of.
ViewState
.Net web forms have a feature called ViewState which allows storing state information on the client. You typically don’t see this, because it is a hidden field (unless you view source). ViewState is not guaranteed to be unique across users. At times, there may be unique values in there that we don’t think about (the user name), but for the most part, ViewState is not sufficient to protect against CSRF. Enter ViewStateUserKey. ViewStateUserKey provides a unique value within the Viewstate per user session. ViewStateUserKey is not enabled by default, and must be set by the developer. This property can be set in the Page_Init event on each page or in the master page. The following is an example of how this can be set:
protected void Page_Init(object sender, EventArgs e) { Page.ViewStateUserKey = Session.SessionId; }
Microsoft has made some changes in Visual Studio 2012. If you create a new Web Forms application, it will include some additional CSRF changes to help mitigate the issue out of the box. The following shows an example of the new Master Page Init method (non-relevant code has been removed):
protected void Page_Init(object sender, EventArgs e) { // The code below helps to protect against XSRF attacks var requestCookie = Request.Cookies[AntiXsrfTokenKey]; if (requestCookie != null && Guid.TryParse(requestCookie.Value, out requestCookieGuidValue)) { // Use the Anti-XSRF token from the cookie _antiXsrfTokenValue = requestCookie.Value; Page.ViewStateUserKey = _antiXsrfTokenValue; } else { // Generate a new Anti-XSRF token and save to the cookie _antiXsrfTokenValue = Guid.NewGuid().ToString("N"); Page.ViewStateUserKey = _antiXsrfTokenValue; } }
In the code above, we can see that the ViewStateUserKey is now being set in the Master Page by default. What a great addition. So what are the limits here?
For starters, and hopefully this is obvious, this technique doesn’t work on requests that don’t use ViewState. Remember the example we used earlier in the post? There is no ViewState there, so this doesn’t offer any protection for that situation. There are also some other situations that could lead to this not working. In .Net 2.0, with EventValidation disabled, ViewStateUserKey would not get validated if the ViewState is empty. I have discussed the ability to pass an empty viewstate before, and this is one of the perks. Many times, ViewState may be present, but the developers do not need it for the processing of the request. If we pass it as __VIEWSTATE= with no content then in 2.0, ViewStateUserKey will not get checked. This was changed in .Net 4.0 where the framework now checks if ViewStateUserKey was set and will check it even if the ViewState is empty. This doesn’t effect requests that don’t use ViewState like the example above.
Nonce or Anti-Forgery Token
Another technique that can be used to protect requests from CSRF is what is called a ‘Nonce’. A Nonce is a single use token that gets included with every request. This token is only known to the user and changes for each request. The idea is that only the requestor of the page with have a valid token to submit the action. In our example above, a new parameter would need to exist such as this:
http://www.jardinesoftware.com/delete.aspx?userid=6&antiforgery=GJ38r4Elke7823SERw
Yes, that value for the antiforgery parameter is just made up. It should be random so it is not guessable by an attacker. This would limit an attacker’s ability to know what YOUR request is to the resource. This is a great way to mitigate CSRF, but can be tricky to implement. ASP.Net MVC has built in functionality for this. For Web forms, you either have to build it, or you can look to OWASP at their CSRFGuard project. I am not sure how stable it is for .Net, but it could be a good starting point.
In Visual Studio 2012, the default WebForm application template attempts to add anti-csrf functionality in to the master page. The following code snippet shows some of the code that does this. (Code has been removed that is not relevant and there is supporting code that is not present from other functions):
protected void Page_Init(object sender, EventArgs e) { // The code below helps to protect against XSRF attacks var requestCookie = Request.Cookies[AntiXsrfTokenKey]; Guid requestCookieGuidValue; if (requestCookie != null && Guid.TryParse(requestCookie.Value, out requestCookieGuidValue)) { // Use the Anti-XSRF token from the cookie _antiXsrfTokenValue = requestCookie.Value; } else { // Generate a new Anti-XSRF token and save to the cookie _antiXsrfTokenValue = Guid.NewGuid().ToString("N"); var responseCookie = new HttpCookie(AntiXsrfTokenKey) { HttpOnly = true, Value = _antiXsrfTokenValue }; if (FormsAuthentication.RequireSSL && Request.IsSecureConnection) { responseCookie.Secure = true; } Response.Cookies.Set(responseCookie); } }
In the code above, we can see the anti-csrf value being generated and stored in the cookies collection. Not shown, the anti-csrf value is also stored in the ViewState as well. This does show that Microsoft is making an attempt to help developer’s protect their applications by providing default implementations like this.
Require Credentials
Another technique that is often employed is to require the user to re-enter their credentials before performing a sensitive transaction. In the example above, when the administrator clicked the link, he would need to enter his password before the delete occurred. This is a fairly effective approach because the attacker doesn’t know the administrator’s password (I hope). The downside to this technique is that users may get upset if they constantly have to re-enter their credentials. By placing too much burden on the users, they may decide to use something else. This must be used sparingly.
CAPTCHA
CAPTCHAs can also be used to help protect against CSRF. Again, this is a unique value per user that the attacker should not know. Like the Credentials solution, it does require more work by the user. Check out Rafal Los’ post on Is unusable the same as ‘secure’? Why security is borked. where he points out the difficulties with a CAPTCHA system when human’s can’t read them.
Use POST Requests
This is not really a mitigation, but more of a recommendation. CSRF can be performed on POST requests too. I just wanted to mention this here to cover it, but this really doesn’t have much weight. All an attacker needs to do is get the victim to visit a page with a hidden form containing the attack request and use JavaScript to auto-submit that form behind the scenes.
Check the Referrer
This is similar to the use of POST requests. It can be bypassed with the proper technologies and isn’t a full solution. This is another item that needs to be implemented properly. I have seen situations where this has been implemented on pages that were ok to access directly and it caused issues.
Conclusion
As you can see, there are many different ways, including more than listed, to protect against CSRF. Microsoft has implemented some nice new changes into the default Visual Studio 2012 Web Form template to help protect against CSRF by default. It is important to understand what the implementation is and its limits of protection. Without this understanding it is easy to overlook a situation where your application could be vulnerable.
SQL Injection in 2013: Lets Work Together to Remediate
Filed under: Development, Security
We just started 2013 and SQL Injection has been a vulnerability plaguing us for over 10 years. It is time to take action. Not that we haven’t been taking action, but it is still prevalent in web applications. We need to set attainable goals. Does it seem attainable that we say we will eradicate all SQL Injection in 2013? Probably not. This is mostly due to legacy applications and the difficulty in modifying their code. There are some goals we can do to stop writing new code vulnerable to SQL Injection. Fortunately, this is not a vulnerability that is not well understood. Here are some thoughts for moving forward.
Don’t write SQL Injection Code
OK, this sounds like what everyone is saying, and it is. Is it difficult to do? No. Like anything, this is something we need to commit to and consciously make an effort to do. Proper SQL Queries are not difficult. Using parameterized queries is easy to do in most languages now. Here is a quick example of a parameterized query in .Net:
using (SqlConnection cn = new SqlConnection()) { using (SqlCommand cmd = new SqlCommand()) { string query = "SELECT fName,lName from Users WHERE fName = @fname"; cmd.CommandText = query; cmd.CommandType = System.Data.CommandType.Text; cmd.Parameters.AddWithValue("@fname", untrustedInput); cmd.Connection = cn; cmd.Connection.Open(); cmd.ExecuteNonQuery(); } }
What about stored procedures? Stored procedures are good, but can be vulnerable to SQL Injection. This is most common when you generate dynamic queries from within the stored procedure. Yes, the parameters are passed to the procedure properly, but then used in an insecure way inside the procedure. If you are unsure if your procedures are vulnerable, look for the use of EXEC or other SQL commands that run SQL code and make sure parameters are handled properly.
Often overlooked is how a Stored Procedure is called. You are using a stored procedure but calling it like so:
string query = "EXEC spGetUser '" + untrustedinput + "'";
The above query can still be vulnerable to SQL Injection by chaining onto the EXEC statement. So even though the stored procedure may be secure, an attacker may be able to run commands (just not see the output).
The key to not writing vulnerable code is to not write it ever. Whether it is a proof of concept, just some test code, or actual production code, take the time to use secure methods. This secure way will be second nature and SQL injection reduction will be on its way.
Supportively Spread the Word
The key here is Supportively!! Yes, we have been talking about SQL injection for years, but have we been doing it the right way, to the right people? First, enough with the “Developers Suckâ€, “Your code sucks!†nonsense. This is not productive and is probably much more destructive to the relationship between security and developers. Second, security practitioners meet up at their cons and talk about this all year long. This may sound crazy, but it is not the security practitioners that are writing the code. We need to get the information into the developer’s hands and minds. Just throwing the information on a blog (like this) or on a website like OWASP or SANS is not enough to get developers the information. I don’t even want to guess at the number of developers that have never even heard of OWASP, but I would venture it is higher than you think. Everyone needs to help spread the word. Security is talking about it, developers need to be talking about it. Major development conferences rarely have any content that is security related, that needs to change. It needs to be thrown in everyone’s lap. If you see someone writing something insecure, let them know so they can learn. We can’t assume everyone knows everything.
Lets start including the secure way of writing SQL Queries in our tutorials, books, classes so all we see is the right way to do it. I mentioned this a year or so ago and everyone cried that it would make the code samples in books and tutorials too long and impossible to follow. First, I disagree that it would be that detrimental. Second, where do developers get a lot of their code? From tutorials, samples, books, classes. We don’t reinvent the wheel when we need to do something. We look for someone that has done it, take the concept, make modifications to work in our situation and run with it. All too often, this leads to a lot of vulnerabilities because we refuse to write secure code that is put out for anyone to use. We all need to get better at this. And if you are the author, maybe it adds a few pages to your book ;).
Take Responsibility
We can no longer blame others for the code we write. Maybe the code was copied from an online resource. As soon as it is in your paws, it is your code now. It is not the fault of MSSQL or Oracle because they allow you to write dynamic SQL queries. This is the power of the system, and some people may just use it. It is our responsibility to know how to use the systems we have. Many frameworks now try to help stop SQL Injection by default. If you are relying on frameworks, know how they work, and keep them patched. We just saw Ruby release a patch to fix a SQL Injection issue.
Conclusion
So maybe this was a lot of rambling, or maybe it will mean something and get a few people thinking about defending against SQL Injection. I apologize for some small tangents, those are part of another post that will be coming soon. The purpose of this post is to start setting some goals that we can achieve in 2013. Not everyone can eat an entire apple in one bite, so lets take some small bites and really chew on them for the year. Lets focus on what we can do and do it well.
Authorization: Bad Implementation
Filed under: Development, Security, Testing
A few years ago, I joined a development team and got a chance to poke around a little bit for security issues. For a team that didn’t think much about security, it didn’t take long to identify some serious vulnerabilities. One of those issues that I saw related to authorization for privileged areas of the application. Authorization is a critical control when it comes to protecting your applications because you don’t want unauthorized users performing actions they should not be able to perform.
The application was designed using security by obscurity: that’s right, if we only display the administrator navigation panel to administrators, no one will ever find the pages. There was no authorization check performed on the page itself. If you were an administrator, the page displayed the links that you could click. If you were not an administrator, no links.
In the security community, we all know (or should know), that this is not acceptable. Unfortunately, we are still working to get all of our security knowledge into the developers’ hands. When this vulnerability was identified, the usual first argument was raised: "No hacker is going to guess the page names and paths." This is pretty common and usually because we don’t think of internal malicious users, or authorized individuals inadvertently sharing this information on forums. Lets not forget DirBuster or other file brute force tools that are available. Remember, just because you think the naming convention is clever, it very well can be found.
The group understood the issue and a developer was tasked to resolve the issue. Great.. We are getting this fixed, and it was a high priority. The problem…. There was no consultation with the application security guy (me at the time) as to the proposed solution. I don’t have all the answers, and anyone that says they do are foolish. However, it is a good idea to discuss with an application security expert when it comes to a large scale remediation to such a vulnerability and here is why.
The developer decided that adding a check to the Page_Init method to check the current user’s role was a good idea. At this point, that is a great idea. Looking deeper at the code, the developer only checked the authorization on the initial page request. In .Net, that would look something like this:
protected void Page_Init(object sender, EventArgs e) { if (!Page.IsPostBack) { //Check the user authorization on initial load if (!Context.User.IsInRole("Admin")) { Response.Redirect("Default.aspx", true); } } }
What happens if the user tricks the page into thinking it is a postback on the initial request? Depending on the system configuration, this can be pretty simple. By default, a little more difficult due to EventValidation being enabled. Unfortunately, this application didn’t use EventValidation.
There are two ways to tell the request that it is a postback:
- Include the __EVENTTARGET parameter.
- Include the __VIEWSTATE parameter.
So lets say we have an admin page that looks like the above code snippet, checking for admins and redirecting if not found. By accessing this page like so would bypass the check for admin and display the page:
http://localhost:49607/Admin.aspx?__EVENTTARGET=
This is an easy oversight to make, because it requires a thorough understanding of how the .Net framework determines postback requests. It gives us a false sense of security because it only takes one user to know these details to then determine how to bypass the check.
Lets be clear here, Although this is possible, there are a lot of factors that tie into if this may or may not work. For example, I have seen many pages that it was possible to do this, but all of the data was loaded on INITIAL page load. For example, the code may have looked like this:
protected void Page_Load(object sender, EventArgs e) { if (!Page.IsPostBack) { LoadDropDownLists(); LoadDefaultData(); } }
In this situation, you may be able to get to the page, but not do anything because the initial data needed hasn’t been loaded. In addition, EventValidation may cause a problem. This can happen because if you attempt a blank ViewState value it could catch that and throw an exception. In .Net 4.0+, even if EventValidation is disabled, ViewStateUserKey use can also block this attempt.
As a developer, it is important to understand how this feature works so we don’t make this simple mistake. It is not much more difficult to change that logic to test the users authorization on every request, rather than just on initial page load.
As a penetration tester, we should be testing this during the assessment to verify that a simple mistake like this has not been implemented and overlooked.
This is another post that shows the importance of a good security configuration for .Net and a solid understanding of how the framework actually works. In .Net 2.0+ EventValidation and ViewStateMac are enabled by default. In Visual Studio 2012, the default Web Form application template also adds an implementation of the ViewStateUserKey. Code Safe everyone.
ViewState XSS: What’s the Deal?
Filed under: Development, Security, Testing
Many of my posts have discussed some of the protections that ASP.Net provides by default. For example, Event Validation, ViewStateMac, and ViewStateUserKey. So what happens when we are not using these protections? Each of these have a different effect on what is possible from an attacker’s stand point so it is important to understand what these features do for us. Many of these are covered in prior posts. I often get asked the question “What can happen if the ViewState is not properly protected?â€Â This can be a difficult question because it depends on how it is not protected, and also how it is used. One thing that can possibly be exploited is Cross-site Scripting (XSS). This post will not dive into what XSS is, as there are many other resources that do that. Instead, I will show how an attacker could take advantage of reflective XSS by using unprotected ViewState.
For this example, I am going to use the most basic of login forms. The form doesn’t even actually work, but it is functional enough to demonstrate how this vulnerability could be exploited. The form contains a user name and password textboxes, a login button, and an asp.net label control that displays copyright information. Although probably not very obvious, our attack vector here is going to be the copyright label.
Why the Label?
You may be wondering why we are going after the label here. The biggest reason is that the developers have probably overlooked output encoding on what would normally be pretty static text. Copyrights do not change that often, and they are usually loaded in the initial page load. All post-backs will then just re-populate the data from the ViewState. That is our entry. Here is a quick look at what the page code looks like:
1: <asp:Content ID="BodyContent" runat="server" ContentPlaceHolderID="MainContent">
2: <span>UserName:</span><asp:TextBox ID="txtUserName" runat="server" />
3: <br />
4: <span>Password:</span><asp:TextBox ID="txtPassword" runat="server" TextMode="Password" />
5: <br />
6: <asp:Button ID="cmdSubmit" runat="server" Text="Login" /><br />
7: <asp:Label ID="lblCopy" runat="server" />
8: </asp:Content>
We can see on line 7 that we have the label control for the copyright data.  Here is the code behind for the page:
1: protected void Page_Load(object sender, EventArgs e)
2: {
3: if (!Page.IsPostBack)
4: {
5: lblCopy.Text = "Copy 2012 Test Company";
6: }
7: }
Here you can see that only on initial page load, we set the copy text. On Postback, this value is set from the ViewState.
The Attack
Now that we have an idea of what the code looks like, lets take a look at how we can take advantage of this. Keep in mind there are many factors that go into this working so it will not work on all systems.
I am going to use Fiddler to do the attack for this example. In most of my posts, I usually use Burp Suite, but there is a cool ViewState Decoder that is available for Fiddler that I want to use here. The following screen shows the login form on the initial load:
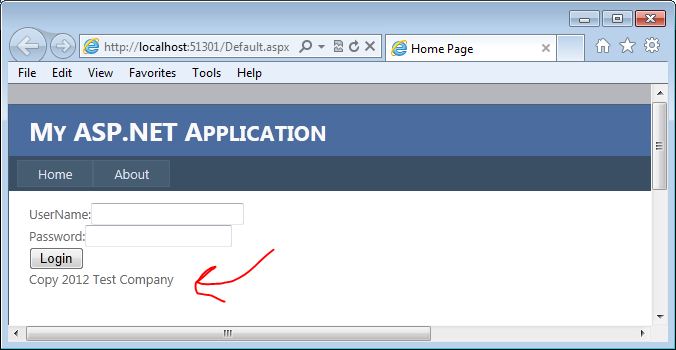
I will set up Fiddler to break before requests so I can intercept the traffic. When I click the login button, fiddler will intercept the request and wait for me to fiddle with the traffic. The next screen shows the traffic intercepted. Note that I have underlined the copy text in the view state decoder. This is where we are going to make our change.
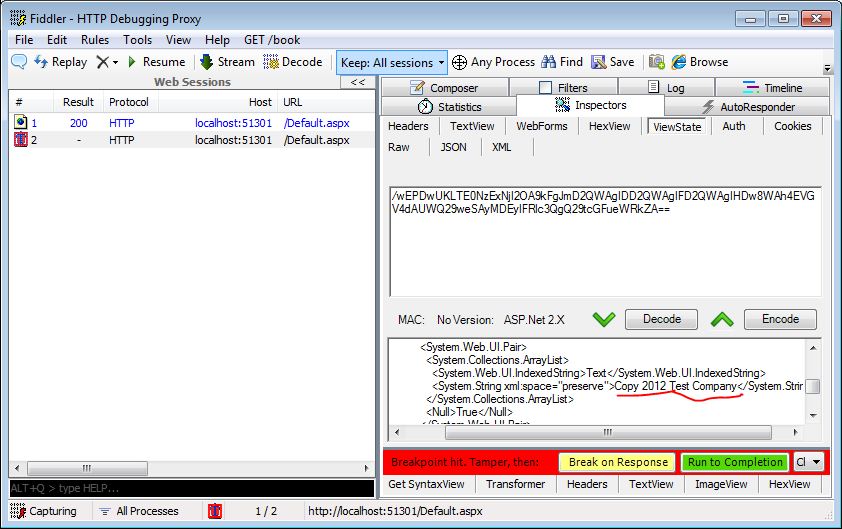
The attack will load in a simple alert box to demonstrate the presence of XSS. To load this in the ViewState Decoder’s XML format, I am going to encode the attack using HTML Entities. I used the encoder at http://ha.ckers.org/xss.html to perform the encoding. The following screen shows the data encoded in the encoder:
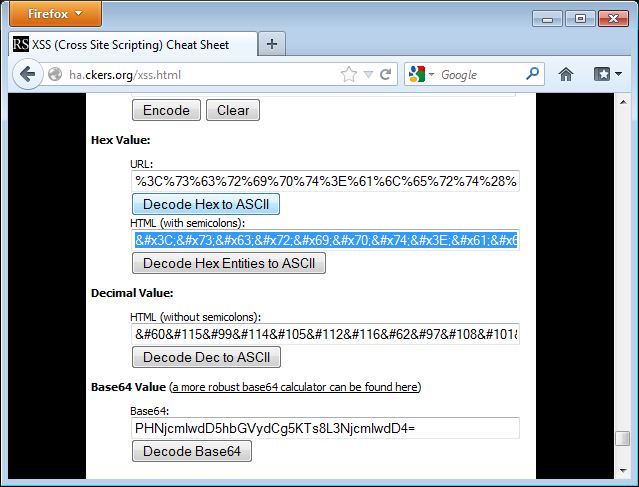
I need to copy this text from the encoder and paste it into the copy right field in the ViewState decoder window. The following image shows this being done:

Now I need to click the “Encode†button for the ViewState. This will automatically update the ViewState field for this request.  Once I do that, I can “Resume†my request and let it complete.  When the request completes, I will see the login page reload, but this time it will pop up an alert box as shown in the next screen:
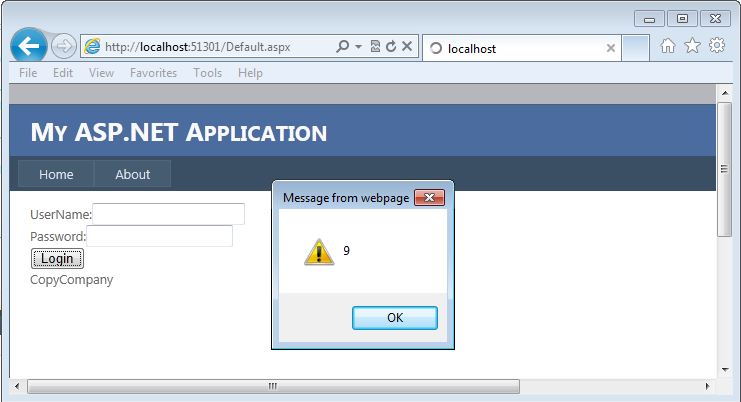
This shows that I was able to perform an XSS attack by manipulating a ViewState parameter. And as I mentioned earlier, this is reflected since it is being reflected from the ViewState. Win for the Attacker.
So What, I Can Attack Myself
Often times, when I talk about this technique, the first response is that the attacker could only run XSS against themselves since this is in the ViewState. How can we get that to our victim. The good news for the attacker…. .Net is going to help us attack our victims here. Without going into the details, the premise is that .Net will read the ViewState value from the GET or POST depending on the request method. So if we send a GET it will read it from the querystring.  So if we make the following request to the page, it will pull the ViewState values from the QueryString and execute the XSS just like the first time we ran it:
http://localhost:51301/Default.aspx?__VIEWSTATE=%2fwEPDwU
KLTE0NzExNjI2OA9kFgJmD2QWAgIDD2QWAgIFD2QWAgIHDw8WAh4
EVGV4dAUlQ29weTxzY3JpcHQ%2bYWxlcnQoOSk7PC9zY3JpcHQ%2b
Q29tcGFueWRkZA%3d%3d&ctl00%24MainContent%24txtUserName=
&ctl00%24MainContent%24txtPassword=
&ctl00%24MainContent%24cmdSubmit=Login
Since we can put this into a GET request, it is easier to send this out in phishing emails or other payloads to get a victim to execute the code. Yes, as a POST, we can get a victim to run this as well, but we are open to so much more when it is a GET request since we don’t have to try and submit a form for this to work.
How to Fix It
Developers can fix this issue quite easily. They need to encode the output for starters. For the encoding to work, however, you should set the value yourself on postback too. So instead of just setting that hard-coded value on initial page load, think about setting it every time. Otherwise the encoding will not solve the problem. Additionally, enable the built in functions like ViewStateMac, which will help prevent an attacker from tampering with the ViewState, or consider encrypting the ViewState.
Final Thoughts
This is a commonly overlooked area of security for .Net developers because there are many assumptions and mis-understandings about how ViewState works in this scenario. The complexity of configuration doesn’t help either. Many times developers think that since it is a hard-coded value.. it can’t be manipulated.  We just saw that under the right circumstances, it very well can be manipulated.
As testers, we need to look for this type of vulnerability and understand it so we can help the developers understand the capabilities of it and how to resolve it. As developers, we need to understand our development language and its features so we don’t overlook these issues. We are all in this together to help decrease the vulnerabilities available in the applications we use.
Updated [11/12/2012]: Uploaded a video demonstrating this concept.
Another Request Validation Bypass?
Filed under: Development, Security
I stumbled across this BugTraq(http://www.securityfocus.com/archive/1/524043) on Security Focus today that indicates another way to bypass ASP.Net’s built in Request Validation feature. It was reported by Zamir Paltiel from Seeker Research Center showing us how using a % symbol in the tag name (ex. <%tag>) makes it possible to bypass Request Validation and apparently some versions of Internet Explorer will actually parse that as a valid tag. Unfortunately, I do not have the specifics of which versions of IE will parse this. My feeble attempts in IE8 and IE9 did not succeed (and yes, I turned off the XSS filter). I did a previous post back in July of 2011 (which you can read here: https://jardinesoftware.net/2011/07/17/bypassing-validaterequest/) which discussed using Unicode-wide characters to bypass request validation.
I am not going to go into all the details of the BugTraq, please read the provided link as Zamir has done a great write up for it. Instead, I would like to talk about the proper way of dealing with this issue. Sure, .Net provides some great built in features, Event Validation, Request Validation, ViewStateMac, etc., but they are just helpers to our overall security cause. If finding out that there is a new way to bypass Request validation opens your application up to Cross-Site Scripting… YOU ARE DOING THINGS WRONG!!! Request Validation is so limited in its own nature that, although it is a nice-to-have, it is not going to stop XSS in your site. We have talked about this time and time again. Input Validation, Output Encoding. Say it with me: Input Validation, Output Encoding. Lets briefly discuss what we mean here (especially you.. the dev whose website is now vulnerable to XSS because you relied solely on Request Validation).
Input Validation
There are many things we can do with input validation, but lets not get too crazy here. Here are some common things we need to think about when doing input validation:
- What TYPE of data are we receiving. If you expect an Integer, then make sure that the value casts to an Integer. If you expect a date-time, then make sure it casts to a date time.
- How long should the data be. If you only want to allow 2 characters (state abbreviation?) then only allow 2 characters.
- Validate the data is in a specific range. If you have a numeric field, say an age, then validate that it is greater than 0 and less than 150, or whatever your business logic requires.
- Define a whitelist of characters allowed. This is big, especially for free-form text. If you only allow letters and numbers then only allow letters and numbers. This can be difficult to define depending on your business requirements. The more you add the better off you will be.
Output Encoding
I know a lot of people will disagree with me on this, but I personally believe that this is where XSS is getting resolved. Sure, we can do strict input validation on the front end. But what if data gets in our application some other way, say a rogue DBA or script running directly against the server. I will not get into all my feelings toward this, but know that I am all for implementing Input Validation. Now, on to Output Encoding. The purpose is to let the client or browser be able to distinguish commands from data. This is done by encoding command characters that the parser understands. For Example, for HTML the < character gets replaced with <. This tells the parser to display the less than character rather than interpret it as the start of a tag definition.
Even with all the input validation in the world, we must be encoding our output to protect against cross site scripting. It is pretty simple to do, although you do have to know what needs encoding and what does not. .Net itself makes this somewhat difficult since some controls auto encode data and others do not.
Can We Fix It?
With little hope that this will get resolved within the .Net framework itself, there are ways that we can update Request Validation ourselves, if you are using 4.0 or higher. Request Validation is Extensible, so it is possible to create your own class to add this check into Request Validation. I have included a simple PROOF OF CONCEPT!!! of attempting to detect this. THIS CODE IS NOT PRODUCTION READY and is ONLY FOR DEMONSTRATION PURPOSES.. USE AT YOUR OWN RISK!. ok enough of that. Below is code that will crudely look for the presence of the combination of <% in the request parameter. There are better ways of doing this, I just wanted to show that this can be done. Keep in mind, that if your application allows the submission of this combination of characters, this would probably not be a good solution. Alright.. the code:
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Web.Util; namespace WebTester { public class NewRequestValidation : RequestValidator { public NewRequestValidation() { } protected override bool IsValidRequestString( HttpContext context, string value, RequestValidationSource requestValidationSource, string collectionKey, out int validationFailureIndex) { validationFailureIndex = -1; // This check is not meant to be production code... // This is just an example of how to set up // a Request Validator override. // Please pick a better way of searching for this. if (value.Contains("<%")) // Look for <%... { return false; } else // Let the default Request Validtion take a look. { return base.IsValidRequestString( context, value, requestValidationSource, collectionKey, out validationFailureIndex); } } } }
In order to get a custom request validation override to work in your application, you must tell the application to use it in the web.config. Below is my sample web.config file updated for this:
<system.web>
<httpRuntime requestValidationType="WebTester.NewRequestValidation"/>
</system.web>
Conclusion
We, as developers, must stop relying on built in items and frameworks to protect us against security vulnerabilities. We must take charge and start practicing secure coding principles so that when a bug like this one is discovered, we can shrug it off and say that we are not worried because we are properly protecting our site.
Hopefully this will not affect many people, but I can assure you that you will start seeing this being tested during authorized penetration tests and criminals. The good news, if you are protected, is that it is going to waste a little bit of the attacker’s time by trying this out. The bad news, and you know who I am talking about, is that your site may now be vulnerable to XSS. BTW, if you were relying solely on Request Validation to protect your site against XSS, you are probably already vulnerable.
Follow Us


